快在当下互联网中无疑是最重要的事情了。老板们强调“一定要快,快速做出新产品,快速迭代,快速占领市场”。
技术也不断快速的迭代,宏观的5G、大数据、人工智能、云计算、物联网等技术使得用户更快的找到内容,微观的Docker容器技术、Kubernetes技术、负载均衡技术、微服务架构等技术使得程序更快速的实现部署。
一切都像汽车上了高速公路一样,开始飞速的运转起来。那么最根本的内容—程序也必须快起来啊。如果底层的程序运行耗时,那么堆叠在上面的架构设计、容器部署、弹性伸缩也是巧妇难为无米之炊,就像汽车引擎不快,即使有了技术高超的驾驶员、行走在高速公路、燃烧最好的汽油,也快不起来。所以代码的运行快速特别重要,今天小编给大家带来的便是cache缓存~
今天分四个模块给大家来深入浅出cache,第一模块是代码块案例;第二模块是程序如何运行;第三模块是cache原理剖析;第四模块是回归案例进行讲解。
在介绍缓存之前,我们从一串代码分析开始,对于二维数组的赋值,有两种写法。
第一种写法是形成了一个100*10的二维数组,第二种写法是10*100的二维数组。
在教科书中的教导使得大部分情况下我们都会使用第一种写法,实质是因为在程序运行效率中,第一种写法运行效率高,背后的原因就是cache缓存了~
在计算机程序执行时所有的指令和数据全从存储器中进行获取,因此在了解cache的工作原理之前,我们先来介绍一下计算机中数据存储的方式。
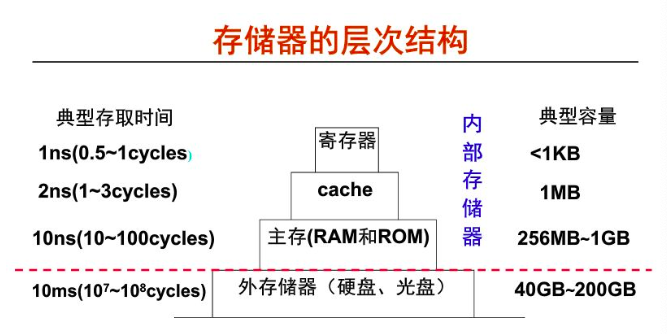
在计算机内部包含有如下存储器,从外到内依次是硬盘、主存(如RAM、ROM)、cache、寄存器,硬盘的话就是平时我们使用的C盘、D盘,可存储文件、视频等,而主存&cache&寄存器用以存储各类程序及处理的数据。
随着技术的发展,各处理器的速度和性能得到了飞跃的提升,作为拍档的存储器速度也必须提升起来,以保持整体系统的平衡。但实际上存储器在容量尤其是访问延时方面的性能增长越来越跟不上处理器性能发展的需要,因此在计算机内部采用层次化的存储器体系结构用以减少二者的差距。
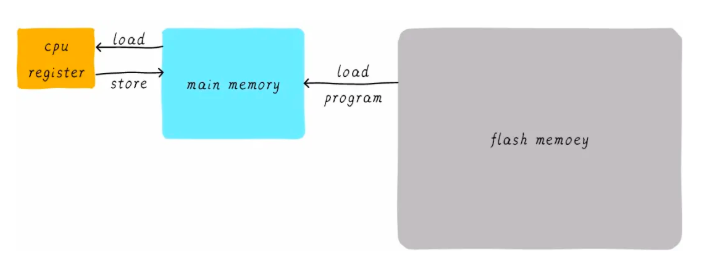
通过刚刚的讲解,我们已经知道程序是运行在主存的RAM当中。那么一个程序是如何运行起来的呢?通常一个程序就是一个进程,当这个进程起来的时候,首先从flash设备中把可执行程序加载在主存中进行运行,当需要对变量进行计算时,在CPU内部的通用寄存器将某地址ad1的变量进行计算。
1)CPU从主存中读取地址ad1的数据到内部通用寄存器X0;
如图所示,寄存器与主存的运行速度相差10倍,也就是说CPU在寄存器获取数据后要等待10倍的时间才能返回到主存,这样的程序执行速度太慢了。
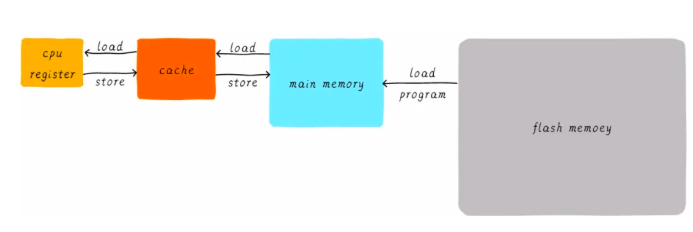
因此cache出现了,在寄存器和主存之前增加了cache,CPU需要对存储器进行读写操作时,先访问cache,如果cache中不存在操作数据时,再从主存中获取,如果主存不存在,再从硬盘中获取,在获取了数据的同时也把该数据放一份在cache中,用以以后的执行获取数据。cache的运行时间为2ns,在整体运行效率上改善了8倍,提升了程序的运行速度。
cache即缓存,将程序执行常用的数据放在cache中,CPU和主存之间直接数据传输的方式就变成了CPU和cache之间直接数据传输,cache则负责与主存之间的数据传输。
如果cache中有CPU需要的数据,这时候成为命中hit,但是当cache中没有想要的数据时(即Miss),CPU仍然需要等待从主存中获取数据,为了提升性能和命中率,在计算机系统中依次引入了多级cachememory、直接映射缓存、两路组相连缓存、全相连缓存。
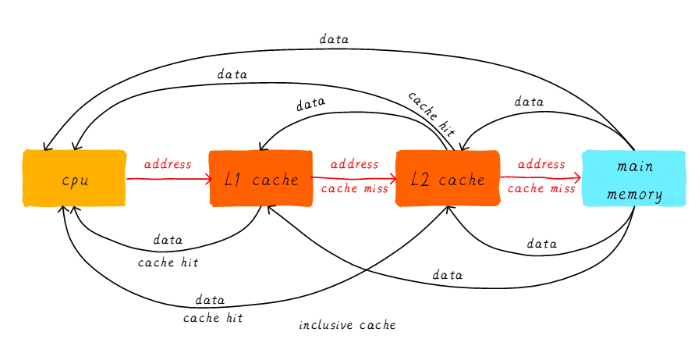
所谓多级缓存,即在CPU寄存器和主存中引入L1cache、L2cache、L3cache,等级越高容量越大速度也越慢.当CPU试图获取某地址的数据时,首先从L1cache中查询,如果命中则返回寄存器,如果不命中则继续从L2cache中进行查询,如果命中,该数据在世界传递给CPU的同时也会传递给L1cache,如果不命中,则继续往L3cache、主存查询。整个的运转流程如图所示。
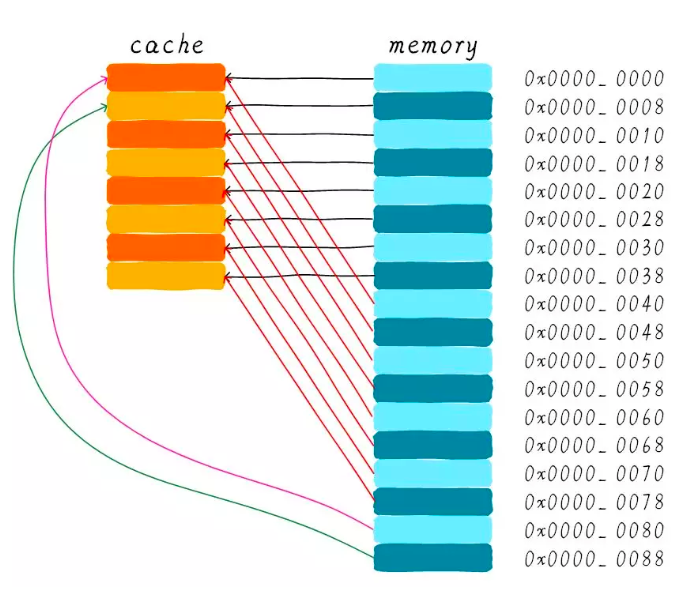
所谓直接映射缓存,则是为了方便cache和主存之间交换信息,将cache和主存空间划分为相等的区域,在主存中的划分区域大小划分为块block,cache中存放主存块的区域称作行line,块block与行line一一对应。比如cache的大小是64bytes,将其划分为64块,那么cacheline就是1字节,只能传输一字节的信息。
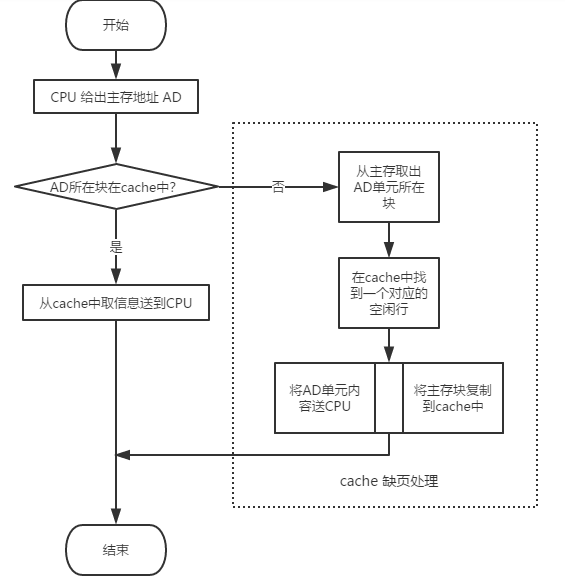
CPU获取数据的方法仍然和多级缓存的方式一样,先从cache中获取,如果没有再从主存中获取,所不同的是将主存中的信息按块复制到cache中,整体流程如下图所示。
所谓全相连映射,则是将每个主存块映射到cache的任意行中,组相连映射是将每个主存块映射到cache固定组的任意行中,直接相连映射则是将每个主存块映射到cache的固定行中。目前我们常见的CPU采用的是组相连映射方式,获得了性能的提升和较低的硬件实现难度。
确定好cache的硬件设计方式后,下一步是cache的数据更新策略和分配策略。更新策略指的是什么情况下进行数据的更新,包含写直通和写回两种策略,写直通策略就是CPU执行命令并且在缓存中命中时,更新cache中的数据和主存的数据,保障cache和主存的数据始终一致,写回策略则是CPU执行命令并且在缓存中命中时只更新cache中的数据,此时cache和主存的数据可能不一致。
分配策略指的是什么情况下进行数据的分配,包含读分配和写分配两种策略,读分配就是CPU去读数据时发生数据缺失,分配一个cacheline缓存从主存读取数据,写分配就是CPU执行写操作cache时发生数据缺失,从主存中加载数据到cacheline中,再更新cacheline的数据。
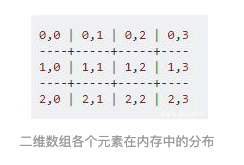
在part1中的关于二维数据的计算有两种方式,写法2效率高于写法1的原因就在于缓存命中率,因为写法2的赋值操作缓存命中率更高一些,所以花的时间更少。对于初接触C语言的同学来说,可能以为二维数组在内存中的分布是这样的:
然而由于计算机中的内存地址是一维的,所以即使是二维数组也按一维进行排列:
写法2获取100个数据的时间如果需要100ns的话,那写法1而获取数据的时间则是10*100=1000ns(需要跳跃10次),因此写法2的速率高于写法1。
那么为什么二者的效率不一样呢?原因就在于缓存命中率不一样。在part3中我们提到CPU采用组相连的硬件设计,获取数据时先访问缓存数据,再访问主存数据。
一般来说cache的大小是64字节,在写法1和写法2中数据的类型都是int型,4字节数据,因此对于64字节的cache中可以缓存16个连续的整数,CPU直接访问cache的这16个数当然比从内存里访问更快。在写法1中虽然加载了16个整数,但数却是跳跃的,相当于需要重复10*1000次,相比写法的方式需要10倍的内存访问次数,此时CPU只能等着内存操作完成再获取数据,因此写法2的速率比较快,写法1比较慢。
总的来说,缓存的出现加快了CPU执行指令的速度,从而加快了程序的执行速度,最后加快了应用的响应速度,给到我们更快更好的用户体验。
这整个过程其实就和租房子差不多,现在在一线城市打拼的年轻人们一般都会租房子,租客就像CPU,找房东直租就像从主存直接获取数据一样,因为房东有自己的工作要做、也有其它的事情要忙,房子的出租对于他来说不是最重要的事情,所以他反馈就不那么技术,所以导致租客等待时间比较长。
中介的出现就像cache的出现一样,拯救了CPU,因为房屋出租成为了中介的工作,所以他会快速的从各处房东那里获取信息,当租客想在西二旗租房时,直接找中介获取该处的房源信息直接看房即可,如果在西二旗没有合适的房源或没有房源,中介会寻找合适的房东进行房源补充,同时反馈给租客,这就像在cache没有命中数据时直接从主存中获取并同步给缓存的原理差不多。
通过上述讲解,相信你已经清楚了程序是如何运行的?回归文章中最初提到的“快速迭代、快速出新产品、快速占领市场”的正确打开方式便是高效运行的代码+化整为零的微服务架构设计+快速部署的容器技术+弹性伸缩的云计算+智能分析的大数据人工智能+5G~









 京公网安备 11010802034997号
京公网安备 11010802034997号