随着互联网的快速发展,分布式的思想已经广泛应用在各个行业中了。分布式是与中心化相对的概念,中心化的思想是把关键的内容集中处理,这样的好处是提高了效率、更专注专一,坏处是如果中心系统挂了,所有的内容都没有了。
分布式的思想是把整个模块分成多个模块去处理,每个人负责一部分,这样的好处是即使某一部分没有了,其它的内容还存在,造成的损失不大,坏处是多模块协调沟通成本高。
比如在企业管理中不会把核心模块只交给某个人负责,而是培养多个人都了解此模块,这样即使核心人员离职了,企业还是可以正常运转,不会有多大影响。
而在计算机系统的世界中,分布式系统的出现是为了用便宜的、普通的机器完成单个计算机无法完成的计算存储任务,更好的利用资源处理更多的任务。
早期的时候一套应用程序全部署在一台机器上,但随着业务量的增长、用户请求的增加,该机器已经不能满足更多的计算存储任务,即使换更好的机器或者单独升级某个组件能力(比如加磁盘、加内存、换更好的CPU)也不能解决问题,这时候只能采用SOA或微服务设计、分布式模式进行部署了,在系统架构上把业务进行拆分,子业务与子业务之间通过网络进行通信,共同协调完成任务,在部署模式上把不同的子业务部署在不同的机器上,子业务扛不住业务压力时再加新的机器支撑。
在业务拆分细粒化、业务部署集群化的情况下就会带来新的问题,不过戴上CAP的帽子后,问题多多的分布式系统也能变得很可爱~
那么什么是CAP定理呢?CAP是一致性Consistency、可用性Availability、分区容错性PartitionTolerance,CAP定理是说这三个目标不能同时满足。
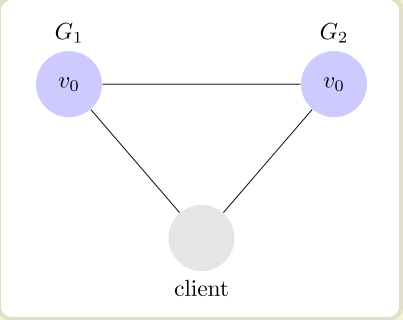
首先我们来看看分区容错性,在分布式系统中,大部分系统都分布在子网络内,每个子网络就是一个区,比如你的服务一台部署在北京,一台部署在上海,这就是两个区。而这两台服务器可能由于网络问题而无法通信,这就是分区容错,一般来说,由于客观原因,分区容错是不能避免的。
下图中G1和G2在不同的区,G1向G2发送消息,但由于链路坏了或其它原因,G2可能收不到。
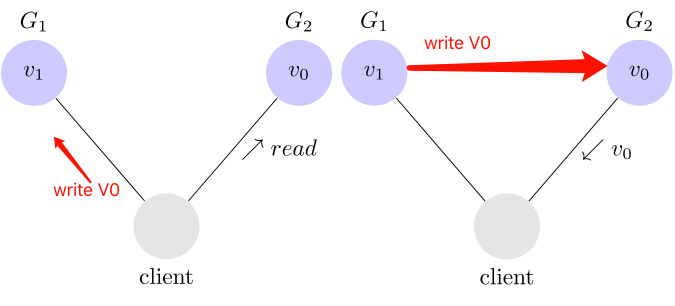
然后我们再来看看一致性,一致性的意思就是数据必须一致。比如你位于北京区域,然后在淘宝下单买了一个商品,这时候在北京区域的订单系统服务器上有了你的订单记录,但是在上海区域的服务器系统没有获取这个信息,所以就会存在你在北京时能看到自己的订单记录,但到了上海后没有订单记录的情况(基于CDN内容分发网络原则,网络请求往最近的服务器区域发送)。如下图所示,客户端往服务器G1写了一条数据V0,G1必须要往G2服务器再写入V0这条数据,这样当客户端向G2服务器请求数据时才能获取V0这条数据的同步,如果G1没有向G2同步写数据,就会出现客户端向G2请求时数据不一致。
最后我们来看看可用性,可用性就是服务任何时候都可以用,只要客户端发起请求,服务器端就必须响应。
那么一致性和可用性为什么不能并存呢?比如为了保障G2的一致性,那么G1在写操作的时候,就必须锁定G2的读操作和写操作,只有数据同步后才能开放G2的读写,在锁定的时候,G2就必然不可用;而如果保障G2的可用性,那么G1在写操作的时候,G2就不能被锁定,数据就会不一致。因此CA只能择一,鱼和熊掌毕竟也不能兼得
在某些业务,比如交易场景中,因为涉及到了金钱,所以必须要数据一致,有任何差错,老板就会拿刀架你脖子上了。
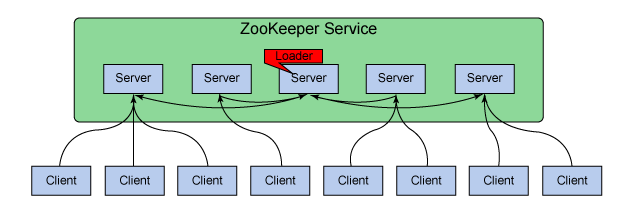
Zookeeper就是保障了数据一致性的方案。在Zookeeper中使用专有的ZAB原子广播协议来保障数据的一致性,在该协议中会包含三个角色Leader领导者、Follower跟随者、Observer观察者,Leader是唯一处理写请求的人;Follower是接收客户端的请求,处理读请求但不处理写请求,并且可以参加或投票Leader的选举(当Leader挂了的时候);Observer是不能参加也不能投票的Follower。
当客户端向服务器发送请求,要写入数据时,服务器会根据自己的角色和该请求的类型进行判断,如果自己是leader那么就处理该请求;如果自己是Follower,那么服务器会根据请求类型进行决策,如果是写请求,就转发给Leader,Leader会给所有的Follower都发一个提议,让大家来投票,如果超过一半的服务器都同意这个提议,那么Leader才会进行操作,从而保障了数据的一致性。
比如在我们刚刚的订单场景中,当用户在客户端发起一个商品购买请求给到订单系统服务器时,服务器集群中的Leader判断这是一个写请求,需要往数据库里插入一条某某用户已购买某某商品的记录,它会把这个记录直接放在自己的服务器的数据库里,并同步给其它的服务器也需要写入该记录。
如果客户端的请求发送给了Follower的服务器,那么它会转发给Leader,Leader就给所有的服务器都发通知,问他们是否可以写入此条记录,如果超过一半的人都表示可以操作,那么Leader、对应的服务器就会把数据写入在服务器里。
在某些业务,比如电商场景中,对于服务的可用性要求非常高,双十一的时候打不开商品的页面简直是会要了女人的命啊,当然打开了就会要了男人的命,哈哈哈,开个小玩笑。
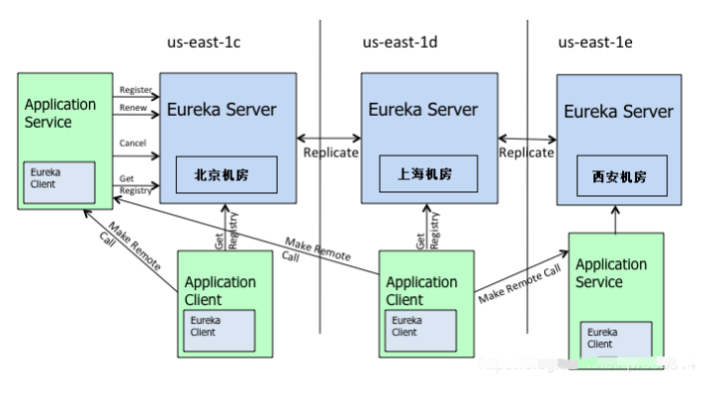
所以在电商场景中服务的可用性是非常重要的,Eureka就是保障了服务可用性的方案。在Eureka集群中,服务器与服务器是通过Replicate来同步数据的,不区分master节点、slave节点,每个应用都指向其它应用,当某个服务器宕机时,该应用就切换到新的服务器节点执行任务,待宕机服务器恢复正常后,再将服务切回来。
如下图所示,还是以订单场景来讲解,在北京、上海、西安机房的服务器里都部署了订单服务的应用程序,但是可能西安机房断电了出了故障,从而导致西安的用户使用订单服务时就不能正常的使用了,但是因为整个大系统采用的是跨地区的高可用的集群部署模式,因此当西安的服务不可用时,用户的请求就会走到上海,由上海的机房来提供服务,同时把数据同步给到北京的服务器,但这时候就会出现一个问题:西安机房的服务器由于断电了没能提供服务,因此断电这段时间内的服务数据时没有的,就出现了北京上海西安的数据不一致的情况。在业务场景中通常采用人工校对、客服等的方式可以解决。
Zookeeper我所欲也,Eureka亦我所欲也,二者不可得兼。可用性我所欲也,一致性亦我所欲也,然二者不可得兼,同学们根据自己的业务场景选择合适的分布式协调框架即可~~





 京公网安备 11010802034997号
京公网安备 11010802034997号